Rubik's Cube Blindfold Method and Improvement
三阶魔方彳亍法盲拧逻辑详解以及一套更符合直觉, 更易于记忆的三阶魔方盲拧编码方案.
前言#
盲拧, 作为一项复原手段, 与我们熟知的速拧有着本质的不同. 速拧依赖于观察魔方状态的实时反馈, 是一个”闭环控制”过程; 而盲拧则是在蒙上双眼后, 仅凭记忆执行一系列操作, 是一个”开环控制”过程. 这两个系统虽然逻辑迥异, 但在一些技巧上却有共通之处.
盲拧入门最大的挑战之一, 就是如何将魔方的状态编码并牢记. 目前流行的”彳亍法”1最初是由 彳亍 于 2006 年在 mf8 论坛上提出的, 其作为三循环二步法虽然强大, 但其编码对于新手而言记忆熟练负担较重. 为了解决这一痛点, 本文在现代”彳亍法”教程234的基础上, 设计了一套更符合直觉, 更易于记忆的编码图, 希望能为广大魔方爱好者打开盲拧世界的大门.
彳亍法盲拧的基本思路可以简要概括为: 首先, 将打乱后的魔方角块和棱块的位置, 分别按照特定规则编码成两个字母字符串. 每个字符串大约包含 20 个英文字母. 记住这两个字符串后, 在蒙眼复原时, 依次按照三循环公式, 将字符串中的每一对字母所对应的块复原到正确位置. 当这两个字符串全部执行完毕, 魔方的角块和棱块也就全部复原了.
因此, 与速拧相比, 学习盲拧彳亍法时主要需要掌握以下四大板块:
- 熟记魔方上每个面所对应的字母编码.
- 新的复原流程.
- 掌握应用在字母编码上的三循环公式:
- 简单版本中, 我们只考虑缓冲块与顶层非对角的两个块的三循环公式, 角块需要 8 个公式, 棱块需要 18 个公式;
- 复杂版本中, 我们考虑任意两个块和缓冲块之间的三循环公式, 角块公式多达 440 个, 棱块公式有 378 个, 总计 818 个公式, 这也是”盲拧彳亍 818”名称的由来.
- 高效记忆这两个总长约 20 个字母的字符串, 方法如下:
- 将每两个字母联想成一个词语进行记忆;
- 用拼音(或双拼)来记忆两个字母;
- 像记电话号码, 车牌号一样, 直接顺序顺口读下来;
- 对于初学者, 建议全部采用联想记忆法. 当盲拧速度提升到两分钟以内时, 可以尝试”记角读棱法”: 用方法 2 记忆较短的角块编码, 用方法 3 记忆较长的棱块编码, 复原时优先还原棱块, 以防遗忘棱块编码.
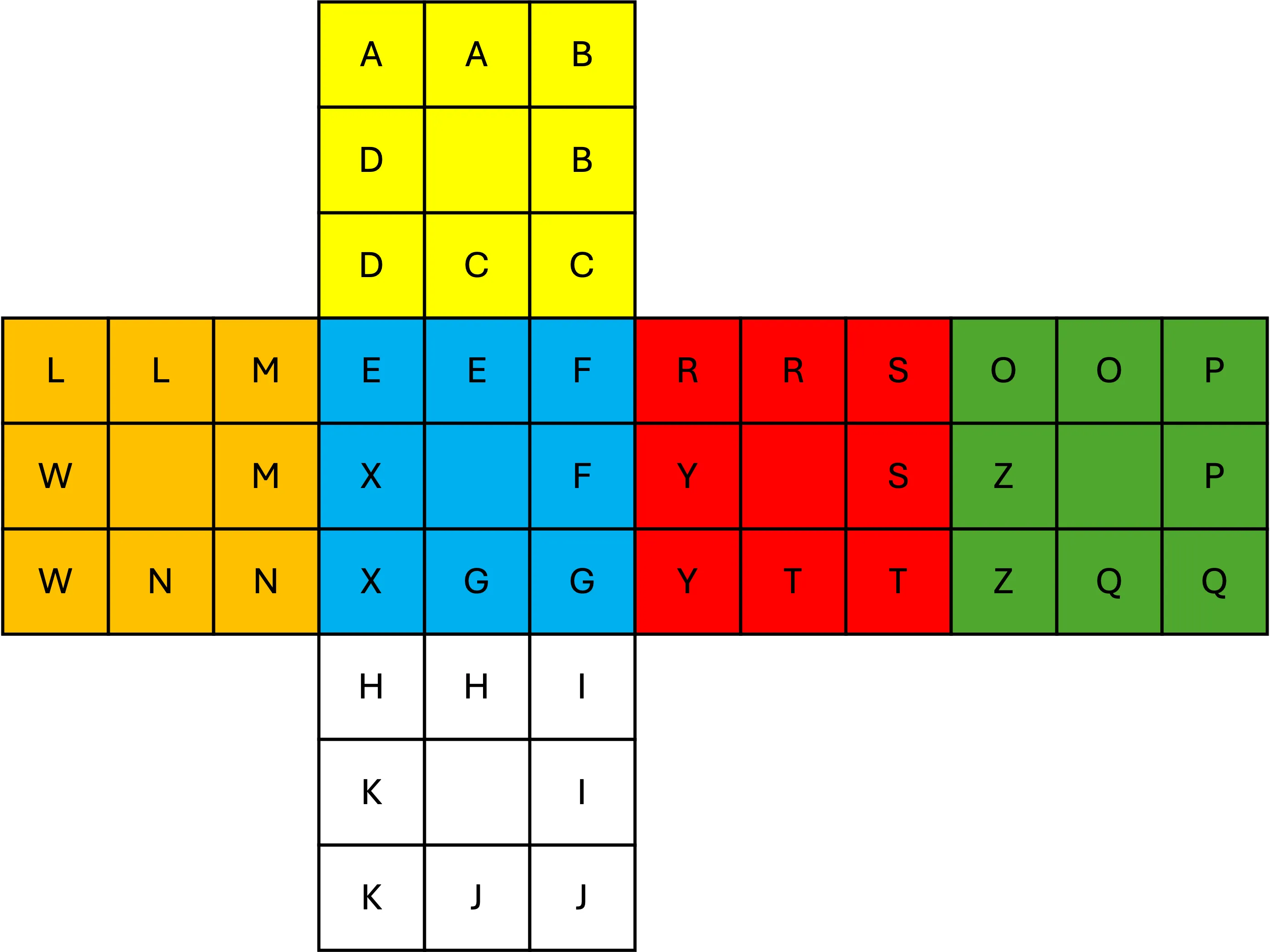
编码#


设计理念#
参考5和6, 我设计了一套新的编码图, 旨在融合 Speffz 编码的逻辑性和中文编码的顺口性, 为初学者提供一套更易上手的盲拧记忆方案.
- 对比彳亍编码: 传统的彳亍编码记忆点较为零散, 新手容易”从入门到放弃”. 我的设计更注重字母排布的规律, 降低了记忆门槛.
- 对比 Speffz 编码: Speffz 作为国际标准, 是由 Ville Seppänen ↗ 和 Rob Holt ↗ 于 2010 年为了方便交流提出的标准化方案, 逻辑性极佳, 但字母本身难以与中文的形象或拼音关联, 不便于中文母语者通过组词等方式记忆.
编码详解#
- 顶层 (U Face): 完全遵循
Speffz编码的A, B, C, D顺序, 一组连续字母, 方便整体记忆. - 前层 (F Face): 字母为
E, F, G, X. 可以联想为这个面正对着”我 (Me)”, 所以以E开头.E, F, G字母连续, 朗朗上口.X则作为一个特殊字母, 与右, 后, 左面的Y, Z, W形成一组. - 右, 后, 左层 (R, B, L Faces): 首字母分别为
R, O, L, 可记为Right(右),Opposite(前层的对面),Left(左). 每个面同样搭配了易于记诵的连续字母. - 底层 (D Face): 字母为
H, I, J, K, 一组连续字母, 方便整体记忆.
编码与复原流程#
前文已经简要介绍了盲拧的基本思路, 下面将详细梳理整个复原流程, 帮助大家更清晰地理解每一步的操作.
由于实际操作中举例讲解非常重要, 因此强烈建议大家配合 彳亍法盲拧教程 ↗ 的视频学习, 视频中的演示和讲解非常直观易懂.
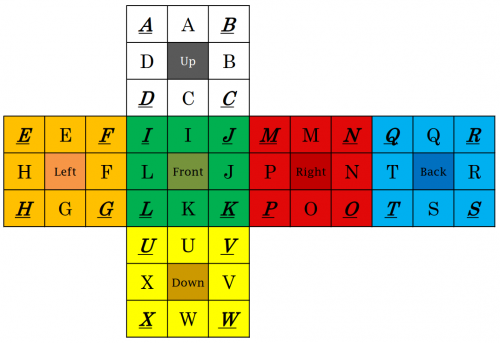
编码——顺序#
编码的起点是缓冲块的上方: 对于棱块来说, 是 UF 棱块的 U 面; 对于角块, 则是 UFR 角块的 U 面. 我们通常先对棱块进行编码, 角块的编码原理与棱块类似, 这里以棱块为例进行说明.
假设当前 UL 棱块的 L 面正好位于缓冲块 UF 的 U 面上, 那么第一个编码就是 L. 这是因为在我设计的编码方案中, UL 棱块的 L 面对应字母 L. 这个编码的含义是: 现在处于 C 位置的棱块, 现在应该被送往 L 位置.
接下来, 观察 L 位置上的棱块颜色, 判断它应该去往哪个位置. 如果它应该前往 B 位置, 那么第二个编码就是 B. 依此类推, 直到所有棱块都被编码完毕.
编码——奇偶校验 (Parity Check)#
当编码长度为奇数时 (棱块和角块编码长度必然同奇偶), 需要进行奇偶校验. 方法很简单: 只需在棱块和角块编码后各加一个 B, 并在复原最后执行一次 Jb Perm 公式即可.
编码——翻色#
如果打乱后有某个棱块或角块虽然位置正确但方向错误, 那么就需要进行翻色操作.
如果需要翻色的块数为偶数, 则这些块一起翻色; 如果为奇数, 则这些块和缓冲块一起翻色.
编码——小循环#
小循环的概念相对抽象, 建议大家先观看实例视频 ↗,或亲自尝试构造一个顺序编码提前结束的小循环案例, 以便更好地理解.
在实际编码过程中, 我们常常会遇到这样一种情况: 顺序编码时, 某个块需要回到缓冲块的位置 (即 C 位置或 E 位置), 但此时还有其他块尚未被编码. 此时, 顺序编码会提前”断开”, 形成一个小循环. 为了继续完成编码, 我们需要主动选择一个尚未被编码的块, 作为新的”起点”, 继续顺序编码, 直到所有块都被编码为止.
如何选择新的起点 (即如何打破小循环) 是许多初学者常见的疑惑, 我们给出选择原则:
- 棱块: 选择与当前缓冲块色相相同的块作为下一个编码目标.
- 角块: 可以任意选择一个未编码的位置继续编码, 无需遵守色相一致原则.
具体操作时, 如果顺序编码遇到某个块应回到缓冲块的 C 位置, 应优先选择一个尚未编码、拥有高级色相的块作为下一个编码目标; 如果遇到应回到 E 位置, 则优先选择拥有低级色相的块. 这样做可以避免在有奇偶校验且编码以 UR 块结尾时, 出现额外的翻色情况.
复原——应用公式#
编码完成后, 就可以开始应用公式进行复原.
例如, 若两个编码为 DB, 则直接使用 M2 U' M U2 M' U' M2 公式进行复原.
复原——Set Up and Reverse#
如果没有记住任意两块之间的复原公式 (共 818 条), 可以只记 26 条基础公式, 配合 Set Up and Reverse 技巧完成复原.
Set Up and Reverse 的原理是: 先将目标两块通过预处理 (Set Up) 转移到 UL 和 UR 位置, 应用已记住的公式进行复原, 最后再按相反步骤 (Reverse) 将两块归位. 这个过程类似于”入栈”和”出栈”.
有两个必须遵守的规则和一个可以不遵守的建议:
三循环公式#
顾名思义, 三循环公式就是调换任意三个块 (棱块或角块) 而不影响其他块的公式.
参考7, 这里给出简单版本的公式, 只包含 UL,UF,UR 三个棱块互换和 UFL,UFR,UBR 三个角块互换的公式. 复杂版本的公式可以参考一九四的三盲818公式 ↗.
棱块公式#
缓冲块为 UF.
其中的备选公式 1 比较适合初学者, 备选公式 2 比较进阶.
| 目标位置 | 备选公式 1 (初学) | 备选公式 2 (进阶) |
|---|---|---|
| DB | R2 U R U R' U' R' U' R' U R' | M2 U' M U2 M' U' M2 |
| BD | R U' R U R U R U' R' U' R2 | M2 U M U2 M' U M2 |
| LB | U' r U R' U' r' R U R U' R' U | L F' L' S' L F L' S |
| BL | U' R U R' U' M' U R U' r' U | S' L F' L' S L F L' |
| LR | M U M' U2 M U M' | |
| RL | M U' M' U2 M U' M' | |
| DR | U' R' U' R U M U' R' U r | S R' F R S' R' F' R |
| RD | U' r' U' R U M' U' R' U R | R' F R S R' F' R S' |
对棱翻色公式: M' U M' U M' U2 M U M U M U2
角块公式#
缓冲块为 UFR.
| 目标位置 | 公式 |
|---|---|
| DB | x' R2 D2 R' U' R D2 R' U R' x |
| BD | x' R U' R D2 R' U R D2 R2 x |
| DO | R' U' D' R' D R U R' D' R D R |
| OD | R' D' R' D R U' R' D' R U D R |
| DS | U' R' U2 R' D' R U2 R' D R2 U |
| SD | U' R2 D' R U2 R' D R U2 R U |
| EB | R2 D R' U2 R D' R' U2 R' |
| BE | R U2 R D R' U2 R D' R2 |
| EO | R U D' R' D' R U2 R' D R D U R' |
| OE | R U' D' R' D' R U2 R' D R D U' R' |
| ES | R' U' R2 D' R2 D R2 U R2 D' R2 D R' |
| SE | R D' R2 D R2 U' R2 D' R2 D R2 U R |
| MB | x' R U R' D R U' R' D' x |
| BM | x' D R U R' D' R U' R' x |
| MO | R' U L U' R U L' U' |
| OM | U L U' R' U L' U' R |
| MS | F' U R' D R U2 R' D' R U F |
| SM | F' U' R' D R U2 R' D' R U' F |
角块翻色采用 (R U R' U') D (U R U' R') D' 等类似的转换机 (Commutator) 翻色法.
奇偶校验#
当编码中出现奇数个字母时, 说明出现了奇偶校验问题, 需要额外执行下述的其中一个公式来修正 (哪一个都行).
- 棱块缓冲与B交换, 角块缓冲与B交换:
R U R' F' R U R' U' R' F R2 U' R' U' - 棱块缓冲与A交换, 角块缓冲与D交换:
U' R U R' U' R' F R2 U' R' U' R U R' F' U
记忆方法#
我采用的是小鹤双拼记忆法8, 这种方法与双拼输入法的原理类似, 即用一个汉字来表示两个字母. 例如, 如果你的盲拧编码只有棱块的 ID, 在双拼输入法中可以对应为 拆 或 柴 字, 因此你只需要记住这个汉字即可.
当然, 有些字母组合可能没有对应的汉字, 这时我们可以用其他拼音方式来替代. 例如, 编码 C 代表缓冲块, 不会被编码, 所以在没有对应汉字的情况下, 可以将双拼的第一个或第二个音节替换为 C.
具体的设计细节可以参考 CubeRoot 双拼记忆法 ↗, 这里不再赘述.